Довольно много людей плохо себе представляют, что такое родство и классификация языков. Что ж, сложно их в этом винить: такие вещи не объясняют в школе. Но разобраться никогда не поздно.
С точки зрения науки, в нормальной ситуации (то есть, если не брать пиджины и креолы) у языка может быть только один предок и в течении его жизни это не может никак измениться.
Сколько бы англицизмов не впитывал современный русский язык, это не может изменить его генетической принадлежности. То есть, язык людей, разговаривающих подобным образом:
всё равно остаётся русским и не становится «ближе к английскому». Почему? Потому что, родство языков – это происхождение, а не сходство. Приведу аналогию. Допустим, девочке не нравится её внешность, унаследованная от мамы, и она хочет быть похожей на некую фотомодель. Девочка красит волосы, вставляет цветные линзы, делает несколько пластических операций. И даже уже всем рассказывает, что она приёмная, а настоящая мать – та самая фотомодель. Вот только экспертиза ДНК совершенно однозначно покажет реальное положение дел.
Аналогичным образом, куча французских заимствований в английском не делает английский романским языком, он так и остаётся германским, и его ближайшие родственники – нидерландский и немецкий, а не испанский и итальянский. Гигантское количество полонизмов в украинском и белорусском нéсколько облегчает изучение польского для носителей этих языков, но никак не меняет того факта, что вместе с русским украинский и белорусский восходят к древнерусскому языку, а значит, именно русский является их ближайшим родственником.
На основании чего происходит установление языкового родства? В целом, для этого стараются привлекать все уровни языка – фонетику, морфологию, синтаксис и лексику. Но важны они для этой процедуры в разной степени. Так, синтаксис и лексика сравнительно быстро меняются и в высокой степени подвержены заимствованию. Фонетика и морфология наоборот к заимствованиям устойчивы (бывают, конечно, случаи заимствования фонем и морфем, но они сравнительно редки).
Недостатком морфологии является то, что она не универсальна. Например, в изолирующих языках типа китайского нет ни склонения, ни спряжения. Но даже если мы берём языки с богатой морфологией, не всё так просто. Скажем, в праславянском языке были развитые системы как именного склонения, так и глагольного спряжения. Глагольных времён, к слову, было пять: настоящее и четыре прошедших (аорист, имперфект, перфект, плюсквамперфект). А вот будущего не было. В большинстве славянских языков эта система подверглась сильному упрощению: вымерли или вымирают аорист, имперфект и плюсквамперфект, перфект становится единственным прошедшим временем, зато появляется будущее. Но в болгарском и македонском система глагола не только не упростилась, но напротив, усложнилась. Зато в этих языках почти исчезла система именного склонения, которая в остальных славянских прекрасно себя чувствует. Другими словами, в морфологии иногда случаются глобальные перестройки, что серьёзно усложняет её применение в установлении родства языков, а также построении классификации. Фонетика в значительной мере лишена этих недостатков, и именно она является важнейшим инструментом лингвиста-компаративиста.
Проиллюстрирую таблицей, как это работает в случае славянских языков. Возьмём несколько фонетических изменений:
а) судьба групп *tj /тй/ и *dj /дй/;
б) судьба носовых гласных;
в) судьба групп CoRC и CъRC (где C – любой согласный, R – r или l, а ъ – особый праславянский гласный).

Комментарий 1: мак. = македонский, схр. = сербохорватский, слвн. = словенский, слвц. = словацкий.
Комментарий 2: чтобы сократить таблицу, я не стал включать в неё лужицкие и полабский языки.
Комментарий 3: щ в болгарском читается как шт; ъ – особый звук (аудио); ќ и ѓ в македонском = кь и гь; ј = й; в сербском ћ = чь, ђ = джь; в алфавитах на базе латиницы c = ц, č = ч; в польском ę = носовое э.
Комментарий 4: в некоторых случаях на исходное состояние наложились более поздние фонетические изменения, при выделении цветом они не учитываются.
Разумеется, классификация славянских языков основывается не только на приведённых в таблице фонетических изменениях, но даже в этой таблице видно, что общая картина сложна (в следующем посте я расскажу, почему), однако русский, украинский и белорусский образуют единую группу. Связано это с тем, что восточнославянские языки – потомки древнерусского, то есть, они пережили длительный период общности, за время которого накопились объединяющие их инновации.
Здесь нужно понимать, что когда мы говорим, что современный русский язык происходит от старорусского, а тот от древнерусского, который является потомком праславянского, и так далее, это серьёзное упрощение. В действительности же, когда язык передаётся из поколения в поколение, это происходит без резких переходов. Ну, то есть, не было такого момента в истории, чтобы один ребёнок сказал другому:
- Что-то я родителей совсем не понимаю.
- Ну ещё бы, они ведь по-праславянски говорят, а мы – уже по-древнерусски.
Язык каждого поколения меняется лишь чуть-чуть, так, что это не мешает детям понимать родителей и бабушек с дедушками. И лишь на больших интервалах можно заметить ощутимую разницу. Поэтому в реальности дела обстоят так, что мы говорим на слегка изменившемся старорусском, который является несколько изменившимся древнерусским, который можно назвать чуть-чуть изменившимся праславянским. И так далее, до первого языка человечества. И все эти названия (старорусский, древнерусский, праславянский, прабалтославянский, праиндоевропейский, праностратический и так далее) – это лишь ярлычки, которые нужны нам для упрощённого описания действительности.
Но давайте вернёмся к таблице. В комментариях к предыдущему посту меня спросили, с чего я вообще взял, что белорусское слово праца «работа» - заимствование из польского. Ответ достаточно прост. Для этого слова реконструируется праформа *portja. Представим, что это слово было уже в праславянском. Тогда оно дало бы следующие результаты (двумя астерисками помечены незасвидетельствованные формы):

Как мы видим, только в чешском мы находим фонетически закономерную форму. При этом известно, что в польском имеются десятки богемизмов, а счёт полонизмам в украинском и белорусском идёт на сотни. Поэтому утверждается, что поляки заимствовали чешское слово, а затем у поляков его переняли украинцы и белорусы. Разумеется, о родстве языков это не говорит ровным счётом ничего. Если какому-нибудь русскому пересадят почку негра, будет ли это означать, что теперь реципиент – тоже негр, а донор – его родственник?
Но давайте вернёмся к лексике. Как уже было сказано выше, она сравнительно легко заимствуется и быстро изменяется. Однако лексика – штука неоднородная. Например, выделяют культурную лексику – ту часть, которая связана с соответствующими культурными явлениями. Очень часто вместе с явлением приходит и название. Так, в современной русской IT-терминологии полно англицизмов, столярная лексика кишит германизмами, а лексика мира моды – галлицизмами. И, конечно же, слова типа компьютер, рубанок и пенсне имеют для установления языкового родства нулевую ценность.
Культурной лексике противопоставляют понятие лексики базисной:
К базисной лексике обычно относят слова, по возможности не зависящие от конкретной культуры и исторической эпохи и присутствующие в любом языке: основные термины родства, названия самых элементарных и универсальных явлений природы и природных объектов (солнце, луна, ночь, вода, камень, земля...), названия частей тела, числительные (по крайней мере, самые первые), простые действия и признаки (знать, видеть, умирать, сидеть, стоять, белый, черный, далеко...). [Бурлак С.А., Старостин С.А. Сравнительно-историческое языкознание]
Это понятие крайне важно для лексикостатистики, о которой я тоже расскажу в следующем посте. Вот так, в частности, выглядит составленный отцом лексикостатистики, Моррисом Сводешом, стословный список базисной лексики:
весь, пепел, кора, живот, большой, птица, кусать, черный, кровь, кость, грудь, жечь, ноготь, облако, холодный, приходить, умирать, собака, пить, сухой, ухо, земля, есть, яйцо, глаз, жир, перо, огонь, рыба, летать, нога, полный, давать, хороший, зеленый, волосы, рука, голова, слышать, сердце, рог, я, убивать, колено, знать, лист, лежать, печень, длинный, вошь, мужчина, много, мясо, рука, гора, рот, имя, шея, новый, ночь, нос, не, один, человек, дождь, красный, корень, дорога, круглый, песок, сказать, видеть, семя, сидеть, кожа, спать, маленький, дым, стоять, звезда, камень, солнце, плавать, хвост, тот, этот, ты, язык, зуб, дерево, два, идти, теплый, вода, мы, что, белый, кто, женщина, желтый.
Авторы таблицы, разобранной в предыдущем посте, как раз старались доказать, что украинский и белорусский более родственны польскому, чем русскому, на основе культурной лексики (чулок, изюм, журнал, сахар, бумага, проволока и так далее). Это очевидный абсурд, и грош цена таким таблицам. Давайте посмотрим, что нам скажет на этот счёт базисная лексика.
Существует проект «Глобальная лексикостатистическая база данных», в рамках которого собраны списки Сводеша для нескольких сотен языков, в том числе ряда славянских. Возьмём списки южнорусского говора деревни Деулино, белорусского диалекта окрестностей Турова и малопольского говора деревни Венцюрка (Więciórka). По некоторым причинам, использовать диалектные данные для подобных целей намного лучше, чем данные литературных языков.
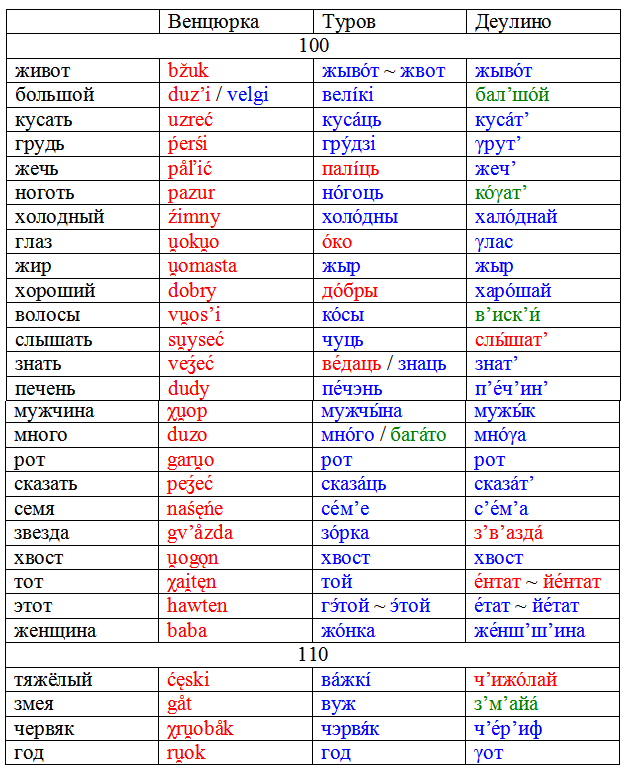
Комментарий 1: в рамках проекта используются несколько расширенные, 110-словные списки. Основная, 100-словная, и дополнительная части в таблице разделены.
Комментарий 2: в таблице я привожу не полные списки, а только те их части, которые различаются.
Комментарий 3: заимствования, которые встречаются во всех трёх списках, в таблице не учтены.
Комментарий 4: списки для проекта собираются по особой методике, отбираются только нейтральные и самые распространённые обозначения, поэтому слова типа великий и ведать в них не учитываются.
Теперь давайте посчитаем количество схождений (как основные указаны цифры по 100-словной части, в скобках – по 110-словному списку):
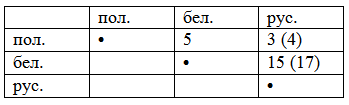
Цифры, на мой взгляд, достаточно красноречивы.
Краткое резюме для многобуквофобов:
1. Родство языков – это происхождение, а не сходство; в нормальном случае у языка может быть только один предок и в течении его жизни это не может никак измениться.
2. Родство языков и его степень нельзя прикинуть «на глазок». Основную роль в это процедуре играют фонетические изменения, в меньшей мере важны морфология и лексика. Лексика при этом годится не любая, а только базисная.
3. Заимствования для установления родства языков вообще не играют никакой роли.
Свежие комментарии